
Exogenous variables
Exogenous variables or external factors are crucial in time series forecasting as they provide additional information that might influence the prediction. These variables could include holiday markers, marketing spending, weather data, or any other external data that correlate with the time series data you are forecasting.
For example, if you’re forecasting ice cream sales, temperature data could serve as a useful exogenous variable. On hotter days, ice cream sales may increase.
To incorporate exogenous variables in TimeGPT, you’ll need to pair each point in your time series data with the corresponding external data.
![]()
1. Import packages
First, we import the required packages and initialize the Nixtla client.
import pandas as pd
from nixtla import NixtlaClient
nixtla_client = NixtlaClient(
# defaults to os.environ.get("NIXTLA_API_KEY")
api_key = 'my_api_key_provided_by_nixtla'
)
Use an Azure AI endpoint
To use an Azure AI endpoint, remember to set also the
base_urlargument:
nixtla_client = NixtlaClient(base_url="you azure ai endpoint", api_key="your api_key")
2. Load data
Let’s see an example on predicting day-ahead electricity prices. The following dataset contains the hourly electricity price (y column) for five markets in Europe and US, identified by the unique_id column. The columns from Exogenous1 to day_6 are exogenous variables that TimeGPT will use to predict the prices.
df = pd.read_csv('https://raw.githubusercontent.com/Nixtla/transfer-learning-time-series/main/datasets/electricity-short-with-ex-vars.csv')
df.head()
| unique_id | ds | y | Exogenous1 | Exogenous2 | day_0 | day_1 | day_2 | day_3 | day_4 | day_5 | day_6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | BE | 2016-10-22 00:00:00 | 70.00 | 57253.0 | 49593.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1 | BE | 2016-10-22 01:00:00 | 37.10 | 51887.0 | 46073.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | BE | 2016-10-22 02:00:00 | 37.10 | 51896.0 | 44927.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 3 | BE | 2016-10-22 03:00:00 | 44.75 | 48428.0 | 44483.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | BE | 2016-10-22 04:00:00 | 37.10 | 46721.0 | 44338.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
3a. Forecasting electricity prices using future exogenous variables
To produce forecasts with future exogenous variables we have to add the future values of the exogenous variables. Let’s read this dataset. In this case, we want to predict 24 steps ahead, therefore each unique_id will have 24 observations.
future_ex_vars_df = pd.read_csv('https://raw.githubusercontent.com/Nixtla/transfer-learning-time-series/main/datasets/electricity-short-future-ex-vars.csv')
future_ex_vars_df.head()
| unique_id | ds | Exogenous1 | Exogenous2 | day_0 | day_1 | day_2 | day_3 | day_4 | day_5 | day_6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | BE | 2016-12-31 00:00:00 | 70318.0 | 64108.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1 | BE | 2016-12-31 01:00:00 | 67898.0 | 62492.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | BE | 2016-12-31 02:00:00 | 68379.0 | 61571.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 3 | BE | 2016-12-31 03:00:00 | 64972.0 | 60381.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | BE | 2016-12-31 04:00:00 | 62900.0 | 60298.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
Let’s call the forecast method, adding this information:
timegpt_fcst_ex_vars_df = nixtla_client.forecast(df=df, X_df=future_ex_vars_df, h=24, level=[80, 90])
timegpt_fcst_ex_vars_df.head()
INFO:nixtla.nixtla_client:Validating inputs...
INFO:nixtla.nixtla_client:Inferred freq: h
INFO:nixtla.nixtla_client:Preprocessing dataframes...
INFO:nixtla.nixtla_client:Querying model metadata...
INFO:nixtla.nixtla_client:Using future exogenous features: ['Exogenous1', 'Exogenous2', 'day_0', 'day_1', 'day_2', 'day_3', 'day_4', 'day_5', 'day_6']
INFO:nixtla.nixtla_client:Calling Forecast Endpoint...
| unique_id | ds | TimeGPT | TimeGPT-hi-80 | TimeGPT-hi-90 | TimeGPT-lo-80 | TimeGPT-lo-90 | |
|---|---|---|---|---|---|---|---|
| 0 | BE | 2016-12-31 00:00:00 | 51.632830 | 61.598820 | 66.088295 | 41.666843 | 37.177372 |
| 1 | BE | 2016-12-31 01:00:00 | 45.750877 | 54.611988 | 60.176445 | 36.889767 | 31.325312 |
| 2 | BE | 2016-12-31 02:00:00 | 39.650543 | 46.256210 | 52.842808 | 33.044876 | 26.458277 |
| 3 | BE | 2016-12-31 03:00:00 | 34.000072 | 44.015310 | 47.429000 | 23.984835 | 20.571144 |
| 4 | BE | 2016-12-31 04:00:00 | 33.785370 | 43.140503 | 48.581240 | 24.430239 | 18.989498 |
Available models in Azure AI
If you are using an Azure AI endpoint, please be sure to set
model="azureai":
nixtla_client.forecast(..., model="azureai")For the public API, we support two models:
timegpt-1andtimegpt-1-long-horizon.By default,
timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.
nixtla_client.plot(
df[['unique_id', 'ds', 'y']],
timegpt_fcst_ex_vars_df,
max_insample_length=365,
level=[80, 90],
)
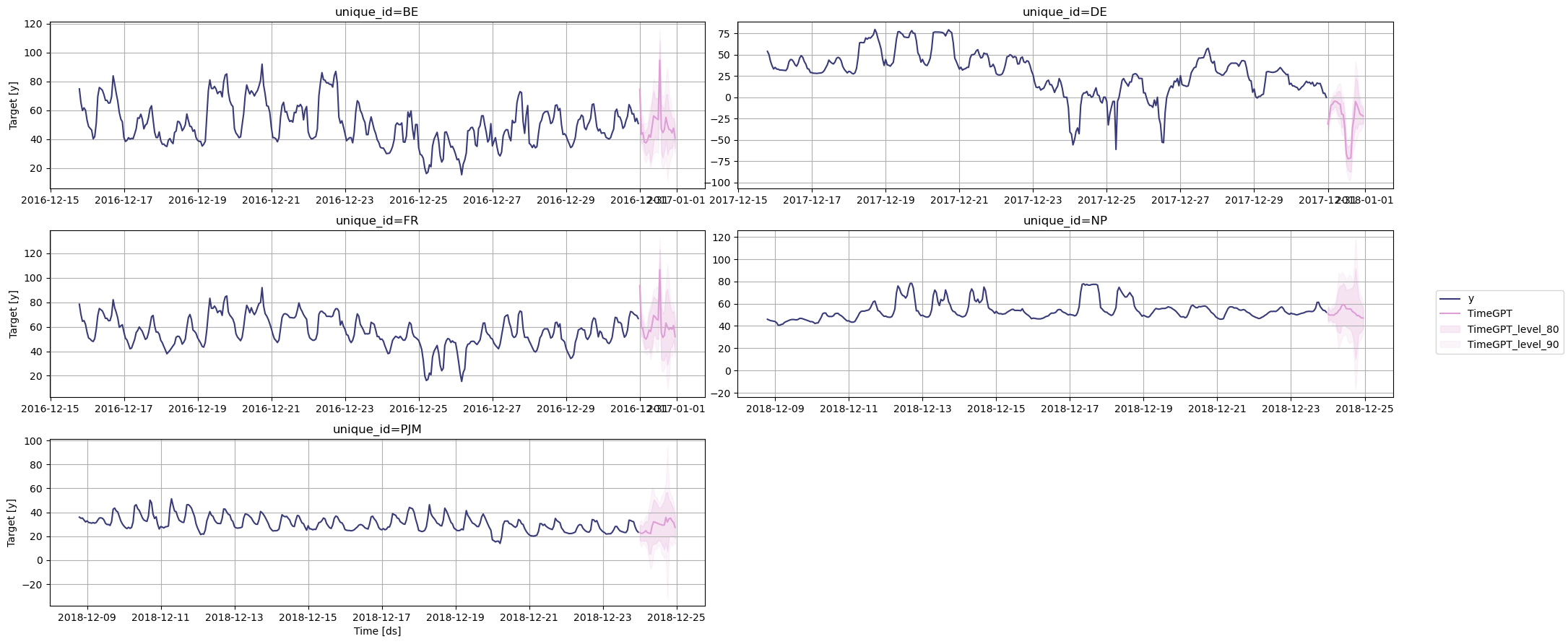
We can also show the importance of the features.
nixtla_client.weights_x.plot.barh(x='features', y='weights')

This plot shows that Exogenous1 and Exogenous2 are the most important for this forecasting task, as they have the largest weight.
3b. Forecasting electricity prices using historic exogenous variables
In the example above, we just loaded the future exogenous variables. Often, these are not available because these variables are unknown. We can also make forecasts using only historic exogenous variables. This can be done by adding the hist_exog_list argument with the list of columns of df to be considered as historical. In that case, we can pass all extra columns available in df as historic exogenous variables using hist_exog_list=['Exogenous1', 'Exogenous2', 'day_0', 'day_1', 'day_2', 'day_3', 'day_4', 'day_5', 'day_6'].
Important
If you include historic exogenous variables in your model, you are implicitly making assumptions about the future of these exogenous variables in your forecast. It is recommended to make these assumptions explicit by making use of future exogenous variables.
Let’s call the forecast method, adding hist_exog_list:
timegpt_fcst_hist_ex_vars_df = nixtla_client.forecast(
df=df,
h=24,
level=[80, 90],
hist_exog_list=['Exogenous1', 'Exogenous2', 'day_0', 'day_1', 'day_2', 'day_3', 'day_4', 'day_5', 'day_6'],
)
timegpt_fcst_hist_ex_vars_df.head()
INFO:nixtla.nixtla_client:Validating inputs...
INFO:nixtla.nixtla_client:Inferred freq: h
INFO:nixtla.nixtla_client:Preprocessing dataframes...
INFO:nixtla.nixtla_client:Using historical exogenous features: ['Exogenous1', 'Exogenous2', 'day_0', 'day_1', 'day_2', 'day_3', 'day_4', 'day_5', 'day_6']
INFO:nixtla.nixtla_client:Calling Forecast Endpoint...
| unique_id | ds | TimeGPT | TimeGPT-hi-80 | TimeGPT-hi-90 | TimeGPT-lo-80 | TimeGPT-lo-90 | |
|---|---|---|---|---|---|---|---|
| 0 | BE | 2016-12-31 00:00:00 | 47.311330 | 57.277317 | 61.766790 | 37.345340 | 32.855870 |
| 1 | BE | 2016-12-31 01:00:00 | 47.142740 | 56.003850 | 61.568306 | 38.281628 | 32.717170 |
| 2 | BE | 2016-12-31 02:00:00 | 47.311474 | 53.917137 | 60.503740 | 40.705810 | 34.119210 |
| 3 | BE | 2016-12-31 03:00:00 | 47.224514 | 57.239750 | 60.653442 | 37.209280 | 33.795586 |
| 4 | BE | 2016-12-31 04:00:00 | 47.266945 | 56.622078 | 62.062817 | 37.911810 | 32.471073 |
Available models in Azure AI
If you are using an Azure AI endpoint, please be sure to set
model="azureai":
nixtla_client.forecast(..., model="azureai")For the public API, we support two models:
timegpt-1andtimegpt-1-long-horizon.By default,
timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.
nixtla_client.plot(
df[['unique_id', 'ds', 'y']],
timegpt_fcst_hist_ex_vars_df,
max_insample_length=365,
level=[80, 90],
)

3c. Forecasting electricity prices using future and historic exogenous variables
A third option is to use both historic and future exogenous variables. For example, we might not have available the future information for Exogenous1 and Exogenous2. In this example, we drop these variables from our future exogenous dataframe (because we assume we do not know the future value of these variables), and add them to hist_exog_list to be considered as historical exogenous variables.
hist_cols = ["Exogenous1", "Exogenous2"]
future_ex_vars_df_limited = future_ex_vars_df.drop(columns=hist_cols)
timegpt_fcst_ex_vars_df_limited = nixtla_client.forecast(df=df, X_df=future_ex_vars_df_limited, h=24, level=[80, 90], hist_exog_list=hist_cols)
INFO:nixtla.nixtla_client:Validating inputs...
INFO:nixtla.nixtla_client:Inferred freq: h
INFO:nixtla.nixtla_client:Preprocessing dataframes...
INFO:nixtla.nixtla_client:Using future exogenous features: ['day_0', 'day_1', 'day_2', 'day_3', 'day_4', 'day_5', 'day_6']
INFO:nixtla.nixtla_client:Using historical exogenous features: ['Exogenous1', 'Exogenous2']
INFO:nixtla.nixtla_client:Calling Forecast Endpoint...
Available models in Azure AI
If you are using an Azure AI endpoint, please be sure to set
model="azureai":
nixtla_client.forecast(..., model="azureai")For the public API, we support two models:
timegpt-1andtimegpt-1-long-horizon.By default,
timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.
nixtla_client.plot(
df[['unique_id', 'ds', 'y']],
timegpt_fcst_ex_vars_df_limited,
max_insample_length=365,
level=[80, 90],
)

Note that TimeGPT informs you which variables are used as historic exogenous and which are used as future exogenous.
3d. Forecasting future exogenous variables
A fourth option in case the future exogenous variables are not available is to forecast them. Below, we’ll show you how we can also forecast Exogenous1 and Exogenous2 separately, so that you can generate the future exogenous variables in case they are not available.
# We read the data and create separate dataframes for the historic exogenous that we want to forecast separately.
df = pd.read_csv('https://raw.githubusercontent.com/Nixtla/transfer-learning-time-series/main/datasets/electricity-short-with-ex-vars.csv')
df_exog1 = df[['unique_id', 'ds', 'Exogenous1']]
df_exog2 = df[['unique_id', 'ds', 'Exogenous2']]
Next, we can use TimeGPT to forecast Exogenous1 and Exogenous2. In this case, we assume these quantities can be separately forecast.
timegpt_fcst_ex1 = nixtla_client.forecast(df=df_exog1, h=24, target_col='Exogenous1')
timegpt_fcst_ex2 = nixtla_client.forecast(df=df_exog2, h=24, target_col='Exogenous2')
INFO:nixtla.nixtla_client:Validating inputs...
INFO:nixtla.nixtla_client:Inferred freq: h
INFO:nixtla.nixtla_client:Preprocessing dataframes...
INFO:nixtla.nixtla_client:Restricting input...
INFO:nixtla.nixtla_client:Calling Forecast Endpoint...
INFO:nixtla.nixtla_client:Validating inputs...
INFO:nixtla.nixtla_client:Inferred freq: h
INFO:nixtla.nixtla_client:Preprocessing dataframes...
INFO:nixtla.nixtla_client:Restricting input...
INFO:nixtla.nixtla_client:Calling Forecast Endpoint...
Available models in Azure AI
If you are using an Azure AI endpoint, please be sure to set
model="azureai":
nixtla_client.forecast(..., model="azureai")For the public API, we support two models:
timegpt-1andtimegpt-1-long-horizon.By default,
timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.
We can now start creating X_df, which contains the future exogenous variables.
timegpt_fcst_ex1 = timegpt_fcst_ex1.rename(columns={'TimeGPT':'Exogenous1'})
timegpt_fcst_ex2 = timegpt_fcst_ex2.rename(columns={'TimeGPT':'Exogenous2'})
X_df = timegpt_fcst_ex1.merge(timegpt_fcst_ex2)
Next, we also need to add the day_0 to day_6 future exogenous variables. These are easy: this is just the weekday, which we can extract from the ds column.
# We have 7 days, for each day a separate column denoting 1/0
for i in range(7):
X_df[f'day_{i}'] = 1 * (pd.to_datetime(X_df['ds']).dt.weekday == i)
We have now created X_df, let’s investigate it:
X_df.head(10)
| unique_id | ds | Exogenous1 | Exogenous2 | day_0 | day_1 | day_2 | day_3 | day_4 | day_5 | day_6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | BE | 2016-12-31 00:00:00 | 70861.410 | 66282.560 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | BE | 2016-12-31 01:00:00 | 67851.830 | 64465.370 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | BE | 2016-12-31 02:00:00 | 67246.660 | 63257.117 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 3 | BE | 2016-12-31 03:00:00 | 64027.203 | 62059.316 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | BE | 2016-12-31 04:00:00 | 61524.086 | 61247.062 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 5 | BE | 2016-12-31 05:00:00 | 63054.086 | 62052.312 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 6 | BE | 2016-12-31 06:00:00 | 65199.473 | 63457.720 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 7 | BE | 2016-12-31 07:00:00 | 68285.770 | 65388.656 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 8 | BE | 2016-12-31 08:00:00 | 72038.484 | 67406.836 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 9 | BE | 2016-12-31 09:00:00 | 72821.190 | 68057.240 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
Let’s compare it to our pre-loaded version:
future_ex_vars_df.head(10)
| unique_id | ds | Exogenous1 | Exogenous2 | day_0 | day_1 | day_2 | day_3 | day_4 | day_5 | day_6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | BE | 2016-12-31 00:00:00 | 70318.0 | 64108.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1 | BE | 2016-12-31 01:00:00 | 67898.0 | 62492.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | BE | 2016-12-31 02:00:00 | 68379.0 | 61571.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 3 | BE | 2016-12-31 03:00:00 | 64972.0 | 60381.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | BE | 2016-12-31 04:00:00 | 62900.0 | 60298.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 5 | BE | 2016-12-31 05:00:00 | 62364.0 | 60339.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 6 | BE | 2016-12-31 06:00:00 | 64242.0 | 62576.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 7 | BE | 2016-12-31 07:00:00 | 65884.0 | 63732.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 8 | BE | 2016-12-31 08:00:00 | 68217.0 | 66235.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 9 | BE | 2016-12-31 09:00:00 | 69921.0 | 66801.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
As you can see, the values for Exogenous1 and Exogenous2 are slightly different, which makes sense because we’ve made a forecast of these values with TimeGPT.
Let’s create a new forecast of our electricity prices with TimeGPT using our new X_df:
timegpt_fcst_ex_vars_df_new = nixtla_client.forecast(df=df, X_df=X_df, h=24, level=[80, 90])
timegpt_fcst_ex_vars_df_new.head()
INFO:nixtla.nixtla_client:Validating inputs...
INFO:nixtla.nixtla_client:Inferred freq: h
INFO:nixtla.nixtla_client:Preprocessing dataframes...
INFO:nixtla.nixtla_client:Using future exogenous features: ['Exogenous1', 'Exogenous2', 'day_0', 'day_1', 'day_2', 'day_3', 'day_4', 'day_5', 'day_6']
INFO:nixtla.nixtla_client:Calling Forecast Endpoint...
| unique_id | ds | TimeGPT | TimeGPT-hi-80 | TimeGPT-hi-90 | TimeGPT-lo-80 | TimeGPT-lo-90 | |
|---|---|---|---|---|---|---|---|
| 0 | BE | 2016-12-31 00:00:00 | 46.987225 | 56.953213 | 61.442684 | 37.021236 | 32.531765 |
| 1 | BE | 2016-12-31 01:00:00 | 25.719133 | 34.580242 | 40.144700 | 16.858023 | 11.293568 |
| 2 | BE | 2016-12-31 02:00:00 | 38.553528 | 45.159195 | 51.745792 | 31.947860 | 25.361261 |
| 3 | BE | 2016-12-31 03:00:00 | 35.771927 | 45.787163 | 49.200855 | 25.756690 | 22.342999 |
| 4 | BE | 2016-12-31 04:00:00 | 34.555115 | 43.910248 | 49.350986 | 25.199984 | 19.759243 |
Available models in Azure AI
If you are using an Azure AI endpoint, please be sure to set
model="azureai":
nixtla_client.forecast(..., model="azureai")For the public API, we support two models:
timegpt-1andtimegpt-1-long-horizon.By default,
timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.
Let’s create a combined dataframe with the two forecasts and plot the values to compare the forecasts.
timegpt_fcst_ex_vars_df = timegpt_fcst_ex_vars_df.rename(columns={'TimeGPT':'TimeGPT-provided_exogenous'})
timegpt_fcst_ex_vars_df_new = timegpt_fcst_ex_vars_df_new.rename(columns={'TimeGPT':'TimeGPT-forecasted_exogenous'})
forecasts = timegpt_fcst_ex_vars_df[['unique_id', 'ds', 'TimeGPT-provided_exogenous']].merge(timegpt_fcst_ex_vars_df_new[['unique_id', 'ds', 'TimeGPT-forecasted_exogenous']])
nixtla_client.plot(
df[['unique_id', 'ds', 'y']],
forecasts,
max_insample_length=365,
)

As you can see, we obtain a slightly different forecast if we use our forecasted exogenous variables.
Updated 5 months ago