
Hierarchical forecasting
In forecasting, we often find ourselves in need of forecasts for both lower- and higher (temporal) granularities, such as product demand forecasts but also product category or product department forecasts. These granularities can be formalized through the use of a hierarchy. In hierarchical forecasting, we create forecasts that are coherent with respect to a pre-specified hierarchy of the underlying time series.
With TimeGPT, we can create forecasts for multiple time series. We can subsequently post-process these forecasts using hierarchical forecasting techniques of HierarchicalForecast.
![]()
1. Import packages
First, we import the required packages and initialize the Nixtla client.
import pandas as pd
import numpy as np
from nixtla import NixtlaClient
nixtla_client = NixtlaClient(
# defaults to os.environ.get("NIXTLA_API_KEY")
api_key = 'my_api_key_provided_by_nixtla'
)
Use an Azure AI endpoint
To use an Azure AI endpoint, set the
base_urlargument:
nixtla_client = NixtlaClient(base_url="you azure ai endpoint", api_key="your api_key")
2. Load data
We use the Australian Tourism dataset, from Forecasting, Principles and Practices which contains data on Australian Tourism. We are interested in forecasts for Australia’s 7 States, 27 Zones and 76 Regions. This constitutes a hierarchy, where forecasts for the lower levels (e.g. the regions Sidney, Blue Mountains and Hunter) should be coherent with the forecasts of the higher levels (e.g. New South Wales).

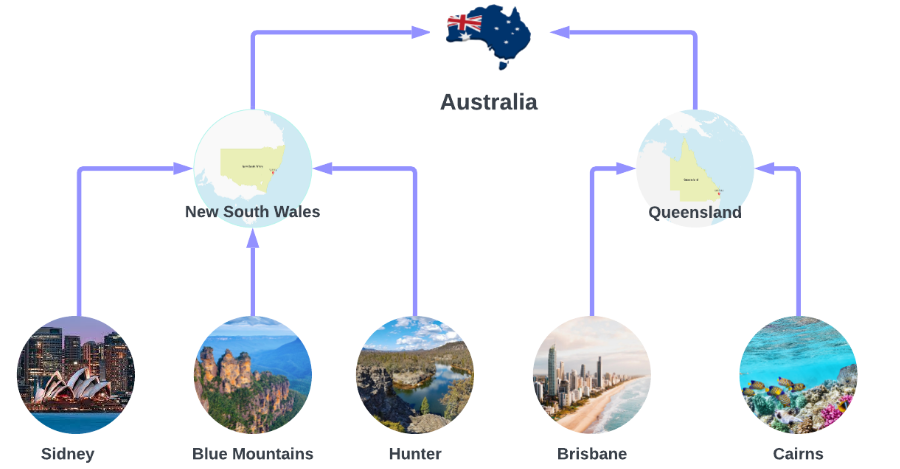
The dataset only contains the time series at the lowest level, so we need to create the time series for all hierarchies.
Y_df = pd.read_csv('https://raw.githubusercontent.com/Nixtla/transfer-learning-time-series/main/datasets/tourism.csv')
Y_df = Y_df.rename({'Trips': 'y', 'Quarter': 'ds'}, axis=1)
Y_df.insert(0, 'Country', 'Australia')
Y_df = Y_df[['Country', 'Region', 'State', 'Purpose', 'ds', 'y']]
Y_df['ds'] = Y_df['ds'].str.replace(r'(\d+) (Q\d)', r'\1-\2', regex=True)
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
Y_df.head(10)
C:\Users\ospra\AppData\Local\Temp\ipykernel_16668\3753786659.py:6: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
| Country | Region | State | Purpose | ds | y | |
|---|---|---|---|---|---|---|
| 0 | Australia | Adelaide | South Australia | Business | 1998-01-01 | 135.077690 |
| 1 | Australia | Adelaide | South Australia | Business | 1998-04-01 | 109.987316 |
| 2 | Australia | Adelaide | South Australia | Business | 1998-07-01 | 166.034687 |
| 3 | Australia | Adelaide | South Australia | Business | 1998-10-01 | 127.160464 |
| 4 | Australia | Adelaide | South Australia | Business | 1999-01-01 | 137.448533 |
| 5 | Australia | Adelaide | South Australia | Business | 1999-04-01 | 199.912586 |
| 6 | Australia | Adelaide | South Australia | Business | 1999-07-01 | 169.355090 |
| 7 | Australia | Adelaide | South Australia | Business | 1999-10-01 | 134.357937 |
| 8 | Australia | Adelaide | South Australia | Business | 2000-01-01 | 154.034398 |
| 9 | Australia | Adelaide | South Australia | Business | 2000-04-01 | 168.776364 |
The dataset can be grouped in the following hierarchical structure.
spec = [
['Country'],
['Country', 'State'],
['Country', 'Purpose'],
['Country', 'State', 'Region'],
['Country', 'State', 'Purpose'],
['Country', 'State', 'Region', 'Purpose']
]
Using the aggregate function from HierarchicalForecast we can get the full set of time series.
Note
You can install
hierarchicalforecastwithpip:pip install hierarchicalforecast
from hierarchicalforecast.utils import aggregate
Y_df, S_df, tags = aggregate(Y_df, spec)
Y_df.head(10)
| unique_id | ds | y | |
|---|---|---|---|
| 0 | Australia | 1998-01-01 | 23182.197269 |
| 1 | Australia | 1998-04-01 | 20323.380067 |
| 2 | Australia | 1998-07-01 | 19826.640511 |
| 3 | Australia | 1998-10-01 | 20830.129891 |
| 4 | Australia | 1999-01-01 | 22087.353380 |
| 5 | Australia | 1999-04-01 | 21458.373285 |
| 6 | Australia | 1999-07-01 | 19914.192508 |
| 7 | Australia | 1999-10-01 | 20027.925640 |
| 8 | Australia | 2000-01-01 | 22339.294779 |
| 9 | Australia | 2000-04-01 | 19941.063482 |
We use the final two years (8 quarters) as test set.
Y_test_df = Y_df.groupby('unique_id').tail(8)
Y_train_df = Y_df.drop(Y_test_df.index)
3. Hierarchical forecasting with TimeGPT
First, we create base forecasts for all the time series with TimeGPT. Note that we set add_history=True, as we will need the in-sample fitted values of TimeGPT.
We will predict 2 years (8 quarters), starting from 01-01-2016.
timegpt_fcst = nixtla_client.forecast(df=Y_train_df, h=8, freq='QS', add_history=True)
INFO:nixtla.nixtla_client:Validating inputs...
INFO:nixtla.nixtla_client:Preprocessing dataframes...
INFO:nixtla.nixtla_client:Querying model metadata...
INFO:nixtla.nixtla_client:Calling Forecast Endpoint...
INFO:nixtla.nixtla_client:Calling Historical Forecast Endpoint...
Available models in Azure AI
If you are using an Azure AI endpoint, please be sure to set
model="azureai":
nixtla_client.forecast(..., model="azureai")For the public API, we support two models:
timegpt-1andtimegpt-1-long-horizon.By default,
timegpt-1is used. Please see this tutorial on how and when to usetimegpt-1-long-horizon.
timegpt_fcst_insample = timegpt_fcst.query("ds < '2016-01-01'")
timegpt_fcst_outsample = timegpt_fcst.query("ds >= '2016-01-01'")
Let’s plot some of the forecasts, starting from the highest aggregation level (Australia), to the lowest level (Australia/Queensland/Brisbane/Holiday). We can see that there is room for improvement in the forecasts.
nixtla_client.plot(
Y_df,
timegpt_fcst_outsample,
max_insample_length=4 * 12,
unique_ids=['Australia', 'Australia/Queensland','Australia/Queensland/Brisbane', 'Australia/Queensland/Brisbane/Holiday']
)
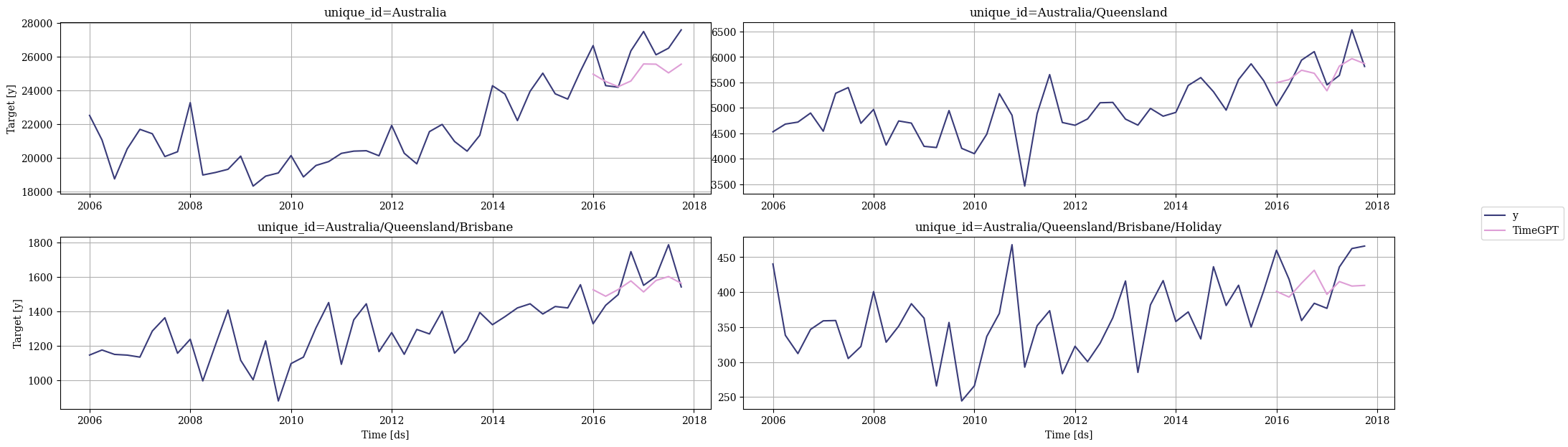
We can make these forecasts coherent to the specified hierarchy by using a HierarchicalReconciliation method from NeuralForecast. We will be using the MinTrace method.
from hierarchicalforecast.methods import MinTrace
from hierarchicalforecast.core import HierarchicalReconciliation
reconcilers = [
MinTrace(method='ols'),
MinTrace(method='mint_shrink'),
]
hrec = HierarchicalReconciliation(reconcilers=reconcilers)
Y_df_with_insample_fcsts = Y_df.copy()
Y_df_with_insample_fcsts = timegpt_fcst_insample.merge(Y_df_with_insample_fcsts)
Y_rec_df = hrec.reconcile(Y_hat_df=timegpt_fcst_outsample, Y_df=Y_df_with_insample_fcsts, S=S_df, tags=tags)
Y_rec_df
| unique_id | ds | TimeGPT | TimeGPT/MinTrace_method-ols | TimeGPT/MinTrace_method-mint_shrink | |
|---|---|---|---|---|---|
| 0 | Australia | 2016-01-01 | 24967.19100 | 25044.408634 | 25394.406211 |
| 1 | Australia | 2016-04-01 | 24528.88300 | 24503.089810 | 24327.212355 |
| 2 | Australia | 2016-07-01 | 24221.77500 | 24083.107812 | 23813.826553 |
| 3 | Australia | 2016-10-01 | 24559.44000 | 24548.038797 | 24174.894203 |
| 4 | Australia | 2017-01-01 | 25570.33800 | 25669.248281 | 25560.277473 |
| ... | ... | ... | ... | ... | ... |
| 3395 | Australia/Western Australia/Experience Perth/V... | 2016-10-01 | 427.81146 | 435.423617 | 434.047102 |
| 3396 | Australia/Western Australia/Experience Perth/V... | 2017-01-01 | 450.71786 | 453.434056 | 459.954598 |
| 3397 | Australia/Western Australia/Experience Perth/V... | 2017-04-01 | 452.17923 | 460.197847 | 470.009789 |
| 3398 | Australia/Western Australia/Experience Perth/V... | 2017-07-01 | 450.68683 | 463.034888 | 482.645932 |
| 3399 | Australia/Western Australia/Experience Perth/V... | 2017-10-01 | 443.31050 | 451.754435 | 474.403379 |
3400 rows × 5 columns
Again, we plot some of the forecasts. We can see a few, mostly minor differences in the forecasts.
nixtla_client.plot(
Y_df,
Y_rec_df,
max_insample_length=4 * 12,
unique_ids=['Australia', 'Australia/Queensland','Australia/Queensland/Brisbane', 'Australia/Queensland/Brisbane/Holiday']
)

Let’s numerically verify the forecasts to the situation where we don’t apply a post-processing step. We can use HierarchicalEvaluation for this.
from hierarchicalforecast.evaluation import evaluate
from utilsforecast.losses import rmse
eval_tags = {}
eval_tags['Total'] = tags['Country']
eval_tags['Purpose'] = tags['Country/Purpose']
eval_tags['State'] = tags['Country/State']
eval_tags['Regions'] = tags['Country/State/Region']
eval_tags['Bottom'] = tags['Country/State/Region/Purpose']
evaluation = evaluate(
df=Y_rec_df.merge(Y_test_df, on=['unique_id', 'ds']),
tags=eval_tags,
train_df=Y_train_df,
metrics=[rmse],
)
numeric_cols = evaluation.select_dtypes(np.number).columns
evaluation[numeric_cols] = evaluation[numeric_cols].map('{:.2f}'.format)
evaluation
| level | metric | TimeGPT | TimeGPT/MinTrace_method-ols | TimeGPT/MinTrace_method-mint_shrink | |
|---|---|---|---|---|---|
| 0 | Total | rmse | 1433.07 | 1436.07 | 1627.43 |
| 1 | Purpose | rmse | 482.09 | 475.64 | 507.50 |
| 2 | State | rmse | 275.85 | 278.39 | 294.28 |
| 3 | Regions | rmse | 49.40 | 47.91 | 47.99 |
| 4 | Bottom | rmse | 19.32 | 19.11 | 18.86 |
| 5 | Overall | rmse | 38.66 | 38.21 | 39.16 |
We made a small improvement in overall RMSE by reconciling the forecasts with MinTrace(ols), and made them slightly worse using MinTrace(mint_shrink), indicating that the base forecasts were relatively strong already.
However, we now have coherent forecasts too - so not only did we make a (small) accuracy improvement, we also got coherency to the hierarchy as a result of our reconciliation step.
References
Updated 4 months ago